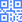首先介绍下freestyle外挂:这是一个根据韵脚,以词搜词的软件。
看着一堆韵脚一致的词 + 一点自己的想象力 = 让你的freestyle开启了外挂
用下面一个例子来说明使用场景

说简单点儿就是在我软件里搜“老娘舅”,你搜到的一堆词里有“要讲究”。
我写了一个微信小程序,总共两个页面,看图



微信小程序实现没太多的技术点,就俩静态页面 和 一个接口请求,暂不赘述,如果你感兴趣想看前端源码的话,在评论里留下邮箱,我会一一发给你们的。
恩,前端是这个样子,那么我们来看后台,就是标题所谓的“不到20行代码写一个freestyle外挂后台”。后台用了一个node.js框架koa,代码非常的简洁,支持async/await语法特性,整个项目除了配置文件,源码就这一个不到20行代码的文件,先看代码

恩 ,乍一看的确加上注释,算起来代码也没到20行,但感觉还是被作者标题党了。
这感觉就像是去电信局拉了条100兆宽带,实际下载速度却只有10M/秒左右。【括号】(1B = 8b ,100Mbps = 12.5MB/秒)。的确,号称不到20行代码的freestyle外挂后台代码里也有这么一个【括号】,也就是代码里的第四行,接下去就让我们来解开这个括号。
如各位在第四行所见,韵脚搜词逻辑实现部分被我封装成了一个 插件“free-style-plugin” ,整个插件只向外暴露一个函数 getWords(keyWord,searchCondition) ,我们只需向其传递两个参数:搜索关键词,搜索类型(全压,单压,英文),它就会向我们返回在词库中搜索到的结果。
首先,我整体地介绍一下我实现韵脚搜词这个功能的主要步骤
- 初始化词库,包括中文词库,英文词库。(把网上找的词库初始化成我自己定义的数据格式)
- 根据搜索条件,提取搜索关键词的韵脚。(中文搜索用的是韵母搜索,英文搜索用的是声母搜索)
- 根据搜索条件,在相应词库中搜索韵脚匹配的单词并返回
我调研后采用的几个第三方库
- 一个中文词库: ling0322/webdict
- 汉语拼音转换库: hotoo/pinyin
- 英文发音库(提取英文单词的发音): The CMU Pronouncing Dictionary
那就从先进步,初始化词库讲起
/**
* 初始化中文词库
*/
function initDictYunMu() {
var promise = new Promise( (resolve, reject) => {
fs.readFile(__dirname + '/data/dict.txt', 'utf-8', function(err, data) {
if (err) {
console.error(err);
} else {
var start = new Date().getTime();
/**
* txt中的词库转换成一个数组
*/
var arrRaw = data.split('\n');
/**
* [arr 数据清洗之后的词库]
*/
var arr = [];
arrRaw.forEach(item => {
var itemSplit = item.split(' ')
/**
* [构建一个新的对象push进数组]
* @name 单词
* @weight 使用频率
* @yunMu 韵母
*/
arr.push({ name: itemSplit[0], weight: itemSplit[1], yunMu: getYunMu(itemSplit[0]) });
})
/**
* 根据单词的 使用频率 & 单词的长短 排序
* 去除单个字的结果 ,用来单压搜索
*/
arr = arr.sort((a, b) => (a.weight - b.weight)).sort((a, b) => (a.name.length - b.name.length)).filter(value => { return value.name.length > 1 })
var end = new Date().getTime();
// console.log(`处理词库220626多词共花费${(end-start)/1000}秒`);
// console.log(arr);
dict = arr;
resolve()
}
});
})
return promise
}
用fs.readFile读取txt词库文件,根据分隔符把数据转换成数组,遍历数组把数组内容转换成我们想要的格式,比如 {name:'外挂',weight: 3, yunMu: ',ai,ua'},再根据词语的使用频率和单词长短排序。 初始化中文词库(220626个词)大概要花7秒钟左右 。
其实刚开始的时候,(因为上面提到的初始化词库是异步的,大概需要7秒时间),npm插件暴露了两个函数: init() , getWords() 。在后台启动的时候先执行 init() ,拦截到路由 /findSameRhymeWords 就执行 getWords()。 但后来发现这样实现有弊端:1.增加插件的使用成本。2.在后台词库未初始化完成的时候请求会报错。
所以代码进行如下改造
- 初始化的时候把这个值缓存下来(也就是代码中的全局变量 dict),之后每次请求进来如果缓存有值就在这个变量里搜索就好了,没值就初始化词库。
- 这里我用了 promise 的写法,让初始化中文词库,初始化英文词库,搜词以比较简洁的形式 同步执行 ,也避免了所谓的回调地狱。
所以npm最终只暴露一个函数: getWords()

第二步,提取搜索关键词的韵脚
这个步骤主要用到的是 上文提到的 pinyin 库,这个库可根据输入中文拿到 中文对应的拼音,声母,虽然没有直接的函数去拿关键词的韵母,但通过(全拼 - 声母)我们可以自己得出关键词的韵母。

第三步,搜索韵脚匹配的单词
中文搜词,遍历整个缓存的词库 ,用indexOf去匹配词,并判断单词末端匹配。

英文搜词,遍历整个词库后,我这边采用正则去匹配,正则可能需要用一个例子解释下:比如说我搜索一个中文 “白头发” ,然后我取到 声母 “btf”,形成正则“B.*T.*F”,然后去英文词库匹配 发音类似的词,比如就能匹配到结果:“ beautiful”。(目前这个功能正处于beta阶段,搜索方式应该还得优化)

软件的细节方面介绍完了,已发布至npm,欢迎各位安装使用
$ npm install free-style-plugin
你也可以参照上面【图四】后台的写法用不到二十行的代码搭建一个韵脚搜词后台,当然如果你对插件源码感兴趣,可以访问 free-style-plugin源码git地址 : nigulasikk/freeStylePlugin ,欢迎各位star,fork,指教。
部署中遇到的其他问题
- node.js环境。先更新node.js至比较新的版本,如(v8.2.1)
- 服务器gcc版本。本地调试都好好的,上服务器发现不行,最后锁定错误发现需要用pinyin库里依赖的jieba词库这边需要高的gcc版本
- https证书。因为微信小程序服务端必须是https的,所以得升级证书。 Let's Encrypt 是一个比较有名的免费证书,里面找了一个能自动升级centos系统对应证书并注入nginx配置的傻瓜式方案: Certbot 。
最后
夏天《中国有嘻哈》很火的时候,我就跟身边的人吹牛逼说我要写这么一个软件,但一直没好好写。现在快半年过去了,正好有点儿时间,就不让吹过的牛逼随青春一笑了之了。
网上看到一句蛮有道理的话,我记了下来: “不要为了押韵而失去歌词的意义” 。
但我想说: “开启freestyle外挂后,punchline中歌词意义和押韵是可以完美融合的”。
最后的最后
我是不懂音乐的,就先做了这么个玩具, 如果有这方面研究很先进的朋友,欢迎联系我qiankaijie1024@gmail.com,提些建议,我提供免费改代码服务哈!